MetaGPT介绍
GitHub:
https://github.com/geekan/MetaGPT
论文地址:
https://zhuanlan.zhihu.com/p/648656905
特点:
介绍:
主要贡献:
MetaGPT:用于多智能体合作框架的元编程
2023年8月1号发布,才7天时间github star 1.3万;这个项目的目标是干掉一个软件公司。可以借助这个项目的思路可以替代健康管理师、法律咨询等纯靠信息的公司体系。
摘要
近期,通过使用由大型语言模型(LLMs)驱动的多智能体,已经在自动任务解决方面取得了显著的进展。但现有研究主要关注简单任务,由于幻觉问题而缺乏对复杂任务的探索和研究。当多个智能体相互交互时,这种幻觉问题无限放大,导致在处理复杂问题时失败。因此,我们引入了MetaGPT,这是一个创新的框架,将有效的人类工作流程作为元编程方法融入到LLM驱动的多智能体协作中。特别是,MetaGPT首先将标准化操作程序(SOPs)编码为提示,促进结构化的协调。然后,它进一步要求模块化输出,赋予智能体与人类专家相当的领域专长,以验证输出并减少累积错误。通过这种方式,MetaGPT利用流水线工作模型为不同的智能体分配多样的角色,从而建立了一个可以有效且有凝聚力地分解复杂多智能体协作问题的框架。我们在协作软件工程任务上进行的实验显示,MetaGPT在产生与现有的基于对话和聊天的多智能体系统相比,更具连贯性的解决方案方面具有能力。这突显了将人类领域知识融入多智能体的潜力,为应对复杂的现实世界挑战开辟了新的途径。
1 引言
利用大型语言模型(LLMs)的多智能体系统为复制和增强人类工作流提供了显著的前景。然而,现有系统往往过于简化了真实世界应用中的复杂性,如最近的研究所示[10,11,12,13,14,15,16]。这些系统主要在通过对话和基于工具的交互中促进有效的协作上存在困难,这导致了如何实现连贯的交互、减轻无效反馈循环和指导有意义的协作参与等挑战[11,12,35,17,29]。多面向的工作流程需要结构良好的标准化操作程序(SOPs)来确保有效性。对真实世界实践的全面理解和整合是至关重要的。解决这些普遍的局限性并整合这些见解可以促进LLM为基础的多智能体系统设计和组织中创新范例的出现,从而增强其有效性和适用性。
此外,通过长期的协作实践,人类在许多领域中都开发了广泛接受的标准化操作程序(SOPs)[1, 2, 3]。这些SOPs在支持任务分解和有效协调中起到了关键作用。例如,在软件工程中,瀑布方法明确了需求分析、系统设计、编码、测试和交付的有序阶段。这种共识的工作流程使大量的工程师能够有效地合作[1, 2]。
此外,人的角色拥有专门针对他们被分配的职责量身定制的专业知识:软件工程师利用编程能力来实现代码,而产品经理利用市场分析来制定商业需求。没有标准化的输出,合作就变得混乱[4, 5, 6]。例如,产品经理必须进行全面的竞争性分析,考察用户需求、行业趋势和竞争对手的提供,并随后创建具有明确标准化结构的产品需求文档(PRDs),概述优先目标以指导开发。这种规范的成果是进展复杂、多面向项目所需的角色之间互相连接的贡献的关键输出[7, 8, 9]。因此,提供明确依赖关系的结构化文档、报告和视觉资料是必不可少的。
在这项工作中,我们介绍MetaGPT,一个基于SOPs的结合现实世界专业知识的开创性多智能体框架。
为了展示我们设计的有效性,我们展示了协作软件开发工作流程和相关的代码实现实验,包括简单的游戏创建和更大的复杂系统设计。与直接调用GPT-3.5或其他开源框架如AutoGPT[18]和AgentVerse[19]相比,MetaGPT处理的软件复杂性明显更大,如由生成的代码行数所量化。
在自动化的端到端过程中,MetaGPT生成了高质量的需求文档、设计工件、流程图和界面规范。这些中间标准化的输出显著提高了最终代码执行的成功率。自动生成的文档还允许人类开发者快速获取和增强领域知识,进一步完善他们自己的需求、设计和代码,促进了更高级的人机交互。总之,我们通过对多面向软件项目的全面实验验证了MetaGPT。无论是定量代码生成基准测试还是完整工作流输出的定性评估,都显示了MetaGPT基于角色的专家代理合作范式所解锁的能力。
总结来说,我们的主要贡献如下:
2 相关工作
基于LLM的自动编程 自动编程是NLP的一个热门研究主题。研究人员训练了分类器来识别并拒绝错误的程序[21],并开发了迭代反馈机制来生成嵌入式控制程序[22]。还有一些最先进的方法利用多数投票来选择候选程序[23],并使用执行结果来提高程序合成[24, 25]。最近,基于LLM的代理[26, 27, 28]促进了自动编程的发展。Li等人[11]提出了一个简单的角色扮演代理框架,通过两个角色的互动实现了基于一句话用户需求的自动编程。此外,Qian等人[29]利用多个代理进行软件开发,但他们没有融合先进的人类团队合作经验。虽然现有的多代理合作[11, 29]目前已经提高了生产率,但它们没有充分利用人类生产实践中的高效工作流程。因此,它们很难解决更复杂的软件工程问题。
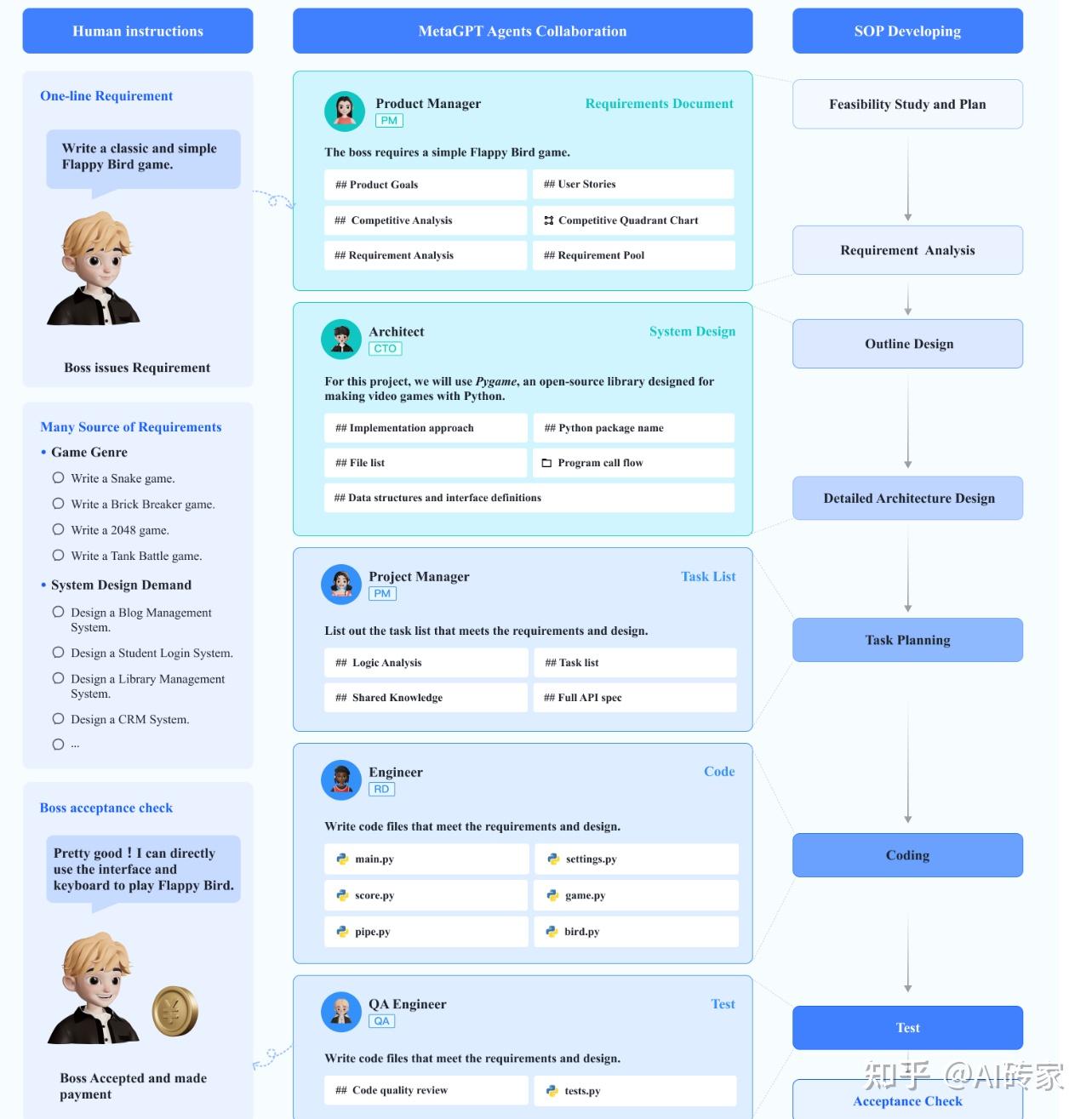
图1:MetaGPT与现实世界中的人类团队在软件开发SOP中的对比描述。MetaGPT的方法展示了其将高层次任务分解为由不同角色(产品经理、架构师、项目经理、工程师)处理的详细可操作组件的能力,从而促进特定角色的专业知识和协调。这种方法反映了人类软件开发团队,但具有提高效率、精确度和一致性的优势。该图说明了MetaGPT如何设计来处理任务复杂性,并促进明确的角色划分,使其成为复杂软件开发场景中的有价值的工具。
此外,还需要提到这篇论文所基于的一系列基础和重要的工作。
这两篇论文都说明了
基于上述设计,我们强调角色劳动分工对复杂任务处理的帮助。
多代理合作 之前的工作已经探索了在合作环境中使用多个LLM来解决复杂任务[32, 29]。动机是通过跨代理互动,LLM可以通过汇聚他们的个人优势来集体展示增强的性能。以前有很多关于多代理的探索,包括集体思考[13, 14, 15, 16]、对话数据集收集[11, 33]、社会学现象研究[10, 34]、效率合作[12, 35, 11, 29]。具体来说:
3 通过标准化操作程序对协作代理进行元编程
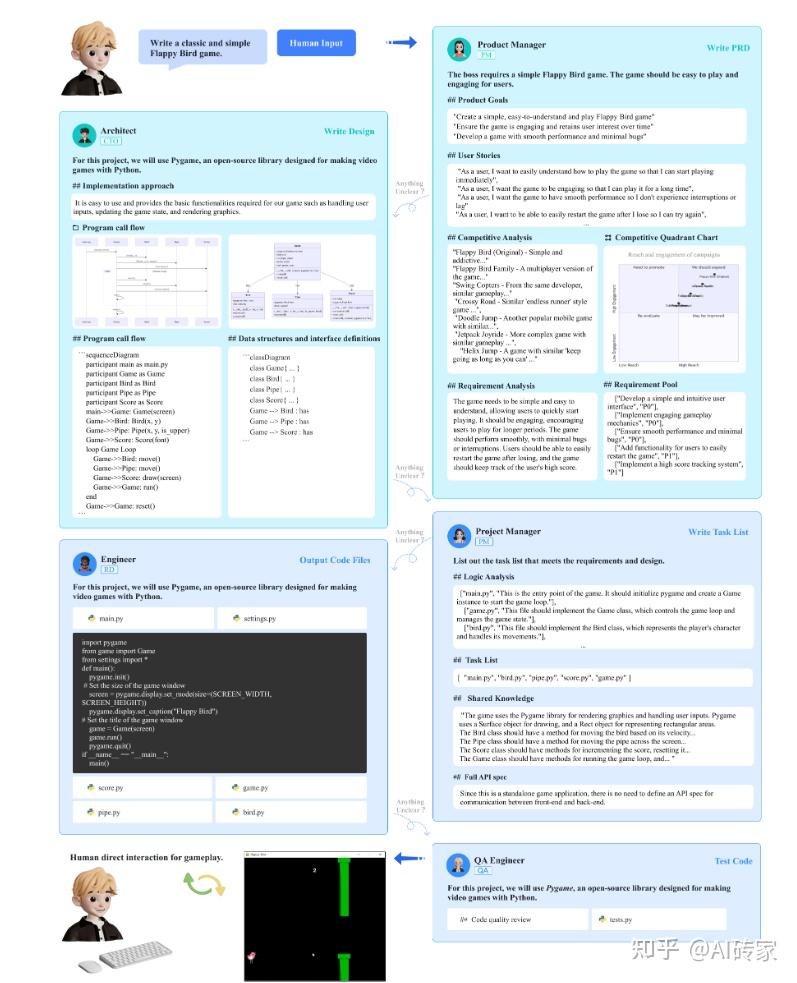
在本节中,我们首先概述了我们提议的元编程多代理协作框架MetaGPT,用于解决复杂的实际问题。然后,我们将在第3.2节中详细说明我们框架中的核心组件设计。为了更好地阐述我们的设计理念,我们选择了软件开发,以说明我们的MetaGPT如何派遣多代理来实现软件开发团队的标准化工作流程(SOP)并完成从头到尾的开发过程,只需要一个人类输入的任务需求。主要的工作流程在图2中描述。在第3.3节,我们提供了一个实际的例子来说明MetaGPT如何协调具有不同角色的多代理来满足一行要求:制作2048滑动瓷砖数字拼图。
3.1 框架概述
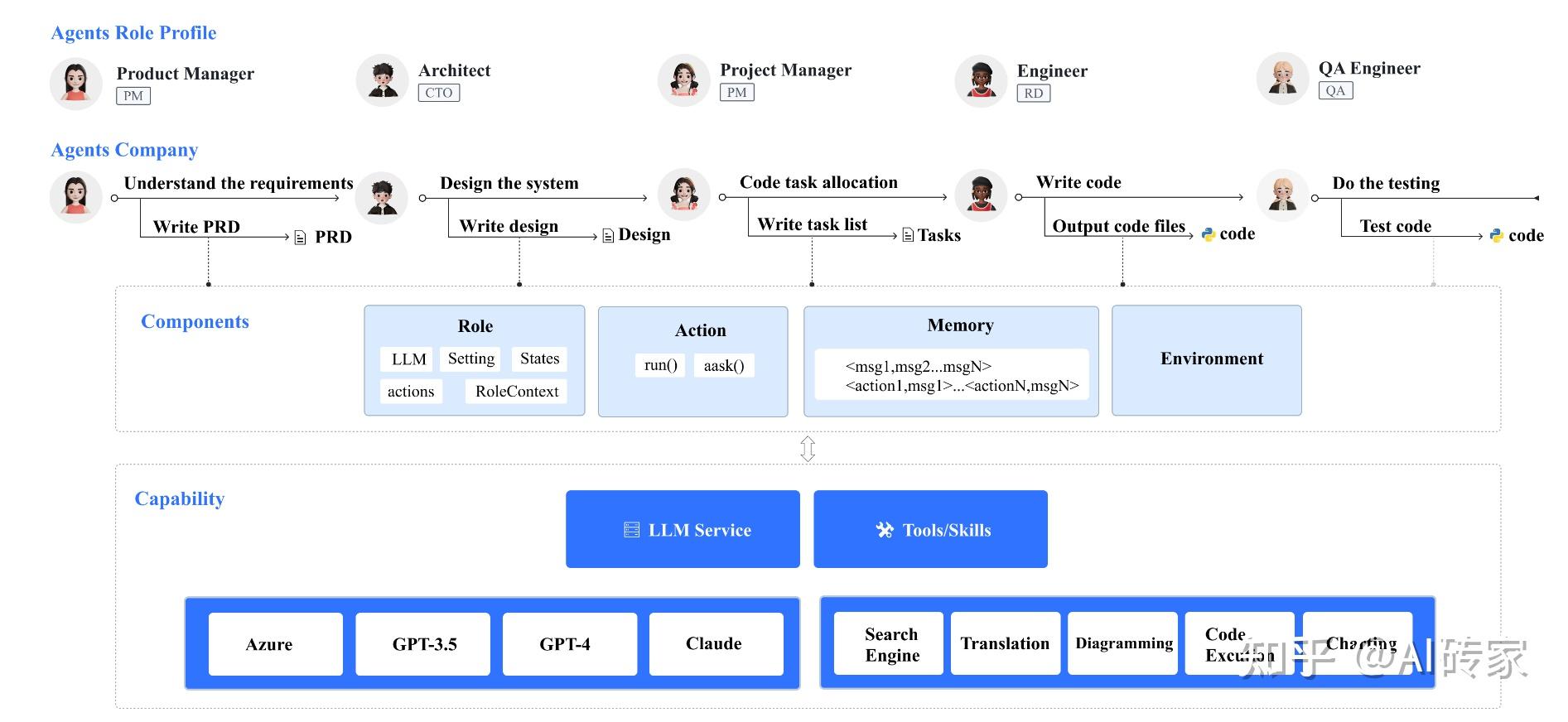
我们通过调查其核心组件架构、知识共享方法以及执行复杂工作流的基本原理,来检查MetaGPT的设计和操作机制。MetaGPT的设计分为两个层次,每个层次都有在支持系统功能方面的明确职责:
基础组件层。这一层建立了对单个代理操作和系统范围内信息交换所必需的核心构建块,包括环境、内存、角色、行动和工具。如图3所示,
这一层为代理提供了在指定角色中功能的基础设施,与彼此及系统进行交互。
图2:MetaGPT框架内的软件开发流程的示意图。此图示意了MetaGPT框架内的顺序软件开发过程。在收到人类的需求后,产品经理开始进行需求和可行性分析。然后,架构师为项目制定具体的技术设计。接下来,项目经理进行序列流程插图以解决每个需求。工程师负责实际的代码开发,然后是进行全面测试的质量保证(
图3:MetaGPT的核心组件概览。
协作层。基于基础组件的基础,这一层协调单个代理,共同解决复杂的问题。它制定了合作的基本机制:知识共享和封装工作流程。
将其划分为基础层和协作层,旨在促进模块化,同时确保单个和集体代理的能力。组件提供了可重用的构建块和实用程序,而协作模块则整合了有目的的协调。
3.2 核心组件设计
在MetaGPT框架中,我们详细定义了关键组件,如环境、内存、角色、行动和工具,并开发了与协作相关的基础能力。
3.2.1 角色定义
MetaGPT框架促进了创建各种专门的角色类,如产品经理、架构师等,它们继承自基础角色类。基础角色类的特点是一组关键属性:名称、概况、目标、约束和描述。具体来说,概况代表角色或职位头衔的领域专长。例如,架构师的概况可能包括软件设计,而产品经理的概况可能集中在产品开发和管理上。目标表示角色寻求达成的主要责任或目标。产品经理的目标可能用自然语言表示为有效地创建一个成功的产品。约束表示角色在执行行动时必须遵守的限制或原则。例如,工程师可能有编写标准化、模块化和可维护代码的约束。约束可能被描述为你编写的代码应该符合PEP8等代码标准,模块化,易于阅读和维护。描述提供了更多的具体身份,以帮助更全面地建立角色。MetaGPT框架的角色初始化使用自然语言详细描述每个角色的职责和约束。这不仅有助于人类理解,而且指导LLMs产生与角色概况一致的行动,从而使每个代理在其角色中都能胜任。我们将此过程定义为锚定代理,这有助于人类将领域特定的责任和能力编码到基于LLM的代理中,同时还为预期功能添加了行为指导。我们将在3.2.2节进一步讨论这个问题。例如,在软件公司,工程师可以使用MetaGPT中的特定于角色的设置进行初始化:角色初始化模板:角色:你是一个[概况],名为[名称],你的目标是[目标],约束是[约束]。
MetaGPT框架提供的全面角色定义使得可以创建高度专门化的基于LLM的代理,每个代理都为特定的领域和目标量身定制。这不仅引入了基于预期功能的行为指导层,而且促进了多样化和专门化代理的创建,每个代理都在其领域中是专家。这导致了能够处理广泛任务的更有效和高效的基于LLM的代理的开发。
在MetaGPT中,智能代理不仅接收并响应信息,而且还观察环境以提取关键细节。这些观察指导了它们的思考和随后的行动。最后,从环境中提取的重要信息被存储在内存中以供将来参考,有效地使系统内的每个代理都成为一个积极的学习者。
它们扮演专门的角色,并遵循某些关键行为和工作流程:
总之,MetaGPT框架为设计和实施具有专门能力的智能代理提供了一种灵活而强大的方法。这些代理可以有效地协作、学习、适应和执行各种任务,使它们在广泛的应用和领域中成为有价值的资产。
3.2.2 提示实例化SOPs
正如之前讨论的,MetaGPT使用提示来实例化真实世界的SOPs为明确定义的代理工作流。我们展示了MetaGPT如何通过自然语言提示将SOPs转化为可执行的操作实例。这个过程涉及使用提示来实例化SOPs,提供基于既定实践的分步指导,并确保复杂序列任务的一致、结构化的执行。
我们首先详细介绍Action类,然后展示如何设计标准化操作级的粒度提示。
在MetaGPT框架内,Action作为代理执行特定任务的原子单元,通过自然语言指定。关键属性包括:
这种方法使LLMs受益,通过减少无关的噪音和集中输入到关键上下文点。结果,提示不仅实例化工作流,还需要根据输入适当地调整执行的上下文意识。
标准化输出模式 这是一个定义预期输出模式的结构表示,用于提取结构化数据。我们提供基本方法将LLM的结果解析为结构化输出。
指令内容 使用标准化输出模式从行动输出中提取的结构化数据。这些信息被封装为一条消息,并最终发布到环境中。
重试机制 通过尝试次数和等待时间定义,以实现对Actions的重试,增强其稳健性。
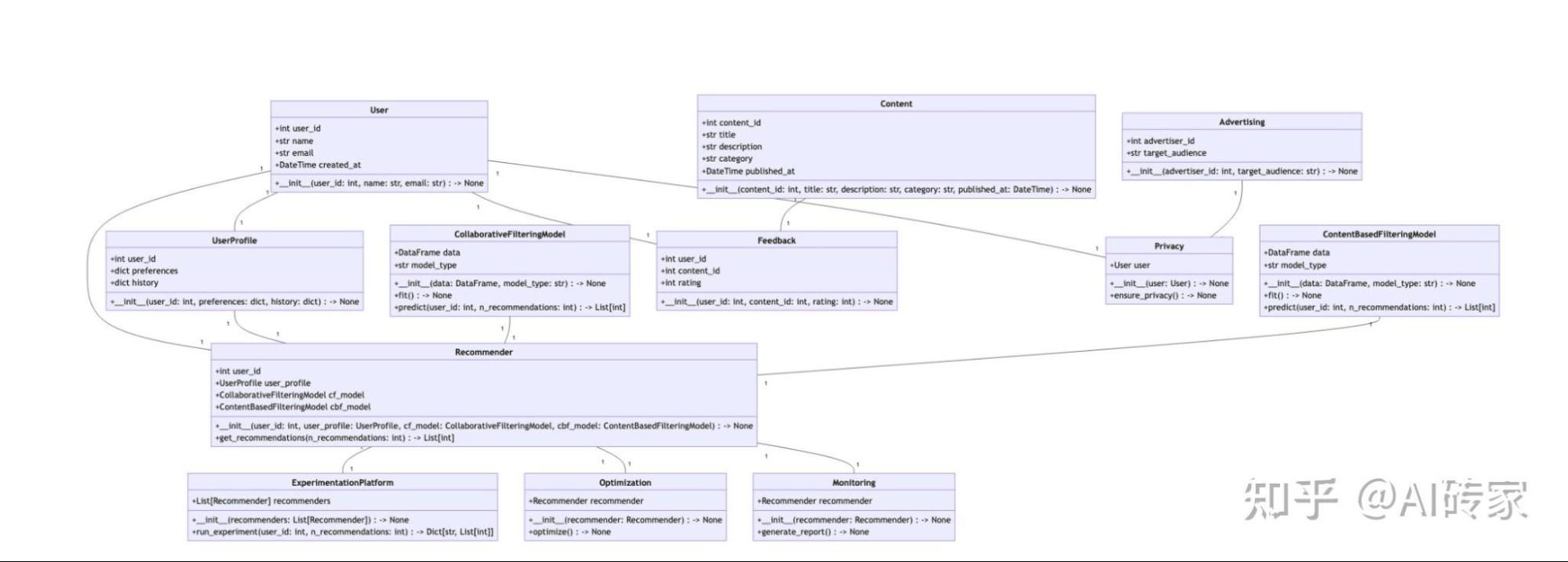
图4:MetaGPT中的架构师代理自动生成的系统界面设计。以内容推荐引擎开发为例。
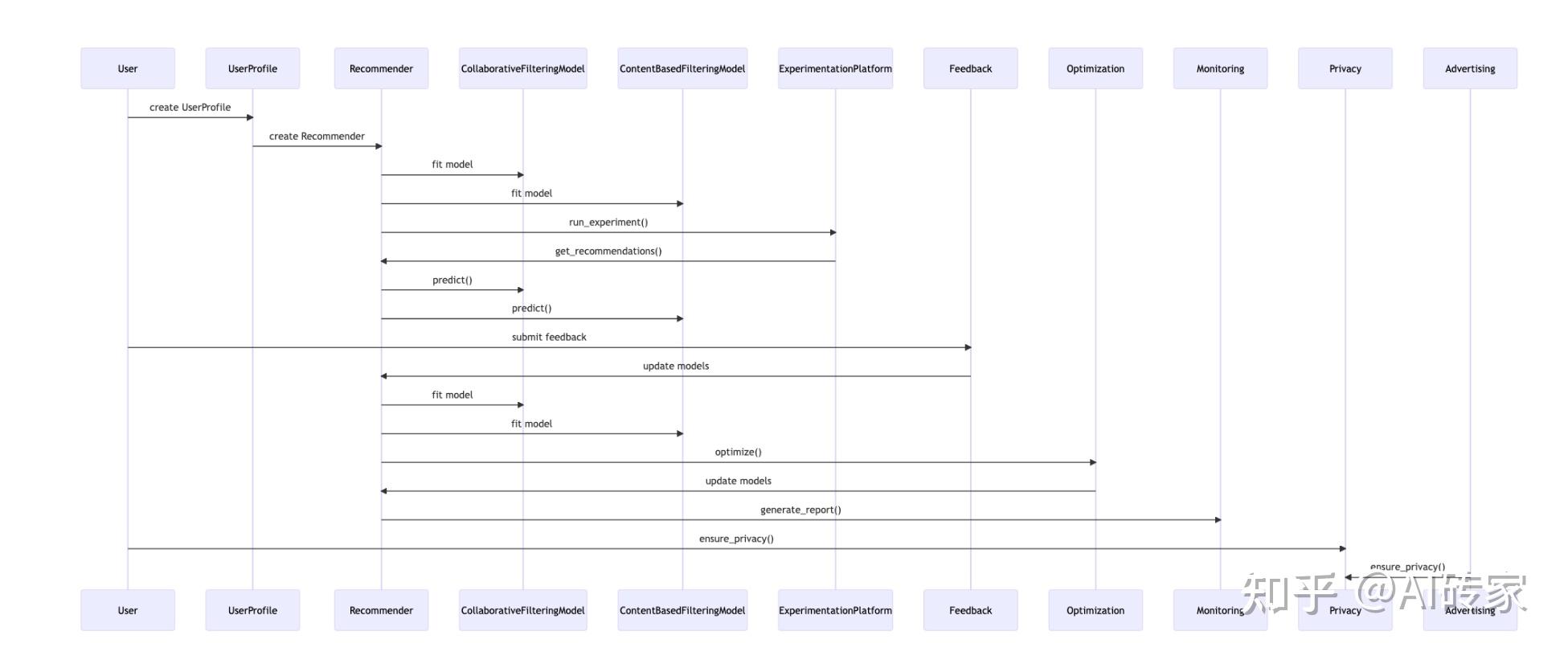
图5:MetaGPT中的架构师代理自动生成的序列流程图。以内容推荐引擎开发为例。
在MetaGPT中的每个Action都需要通过编码高质量的专家级结构关键点来定义标准化的输出内容。然后,LLM根据此标准化输出模式针对特定任务来完善Action。本质上,我们为每个Action提供一个符合标准的提示模板,该模板可以引导LLM的行为以生成规范化的输出。
我们为MetaGPT中的ProductManager代理定义了一个WritePRD Action来展示这个过程。在此Action中,我们通过指定所需的输出,如产品目标、用户故事、竞争分析、需求分析和优先级需求池,来整合领域专家知识。这些输出封装了根据行业惯例的产品管理中的关键工件和实践。此外,我们为ProductManager代理实例化了支持技能,例如web搜索API来丰富分析,以及像mermaid [39]这样的绘图工具来可视化竞争四分图表。
如图2所示,ProductManager有效地结构化输出部分。通过为代理装备与真实世界的产品管理职责相一致的这些补充能力,WritePRD Action可以在遵循标准化工作流的同时执行子任务。
通过这种方式,WritePRD Action展示了如何将领域知识、输出模式和辅助技能结合起来,将高级SOPs转化为代理可执行和可定制的程序。通过将真实世界的最佳实践提取到Action规范中,MetaGPT将抽象的专家知识与针对协作工作流的结构化执行相结合。而且,每个动作不仅仅是一个孤立的功能。它构成了一套全面的指导方针的一部分,指导LLM在其角色范围内的行为,确保产生高质量、结构化、特定于任务的输出。
3.2.3 为标准化输出的Actions
MetaGPT的实例化工作流的有效性在很大程度上依赖于为每个动作建立标准化的输出。这些输出借鉴专家领域知识和行业最佳实践,将工作流适应于特定的角色和上下文。结构化输出设计有以下目的:
我们的方法的能力在超越简单游戏示例的更复杂的系统设计上得到了展示,如内容推荐引擎、搜索算法框架和基于LLM的操作系统。更详细的结果可以在附录A中找到。
如图4所示,架构师代理生成了一个详细的系统级图,说明软件架构。这个图包括了User、CollaborativeFilteringModel和Recommender等关键模块的清晰定义,并补充了每个模块内部的重要字段和方法的详细信息。这种清晰性有助于工程师理解核心工作流和功能组件。此外,设计还包括模块之间的调用关系,遵循关注点分离和系统级的松散耦合的原则。从人类自然语言到结构化技术设计的转化提供了可行的细节,可以促进工程实现,超越高级概述。
尽管系统设计提供了一个整体框架和模块设计,但它本身对工程师实现复杂系统编码还不足够。工程师仍然需要关于如何在模块内部和模块之间执行操作的额外细节,以将设计转化为功能代码。如图5所示,架构师还根据系统界面设计创建了一个序列流程图,描述了执行功能所需的过程、涉及的对象和它们之间交换的消息序列。如前所述,这些补充细节使工程师和其他合作者,如负责详细代码设计工作的项目经理的工作变得更容易。
因此,架构师角色的一致、协同的输出对于通过简化工程师将规范转化为功能代码的任务来提高代码质量是至关重要的。他们减少了由自由形式的自然语言引起的模糊性、误解和混淆。
总之,MetaGPT中标准化输出的设计和实施为处理复杂任务提供了强大的工具。将定义在自然语言中的复杂任务转化为结构化和标准化的输出可以促进协作一致性,减少可能导致不连贯的过多对话轮次的需求。此外,它允许清晰稳定地表示结构信息,仅通过自然语言很难明确地传达这些信息,特别是对于基于LLM的代理。通过提供这些结构化和标准化的输出,不同的代理获得了对其任务和职责的清晰、一致的理解。这种方法不仅简化了沟通,而且增强了基于LLM的多代理系统更有效地管理和执行复杂任务的能力。
3.2.4 知识共享机制与定制化知识管理
在MetaGPT中,每个代理主动地通过从共享环境日志中检索相关的历史消息来策划个性化的知识。代理不是被动地依赖对话,而是利用基于角色的兴趣来提取相关信息。具体来说,环境复制消息以提供统一的数据存储库。代理根据对其角色有意义的消息类型注册订阅。匹配的消息会自动分发以通知适当的代理。在内部,代理通过内容、发布代理和其他属性维护一个内存缓存,对订阅的消息进行索引。检索机制允许代理根据需要查询这个存储,以获得上下文细节。更新在链接的代理记忆之间同步,以保持一致的视图。这种分散而统一的访问模式反映了人类组织是如何运作的 - 团队成员有共享的记录,但围绕他们的职责定制视图。通过围绕代理角色构建信息流,MetaGPT允许自治代理有效地自助适当的知识。
如前所述,MetaGPT中的每个代理都维护一个内存缓存,对与其角色相关的订阅消息进行索引,从而实现个性化的知识策划。具体来说,消息的集中环境复制创建了一个统一的数据源。然后,代理注册订阅,以从这个源自动获取与角色相关的消息。在内部,代理的内存缓存按内容、来源和属性进行索引,以实现快速的上下文检索。这个分散而联合的知识生态系统不是一刀切的沟通方式,它反映了人类团队如何围绕个体职责定制信息视图,同时依赖共享记录。
通过围绕代理角色对信息流进行对齐,MetaGPT使自治代理能够有效地提供适当的知识。这种模式反映了人类组织是如何运作的 - 虽然每个人都可以访问共享的记录,但个人根据他们的具体职责定制他们的观点。
MetaGPT将集中的消息共享与个性化的基于角色的内存缓存相结合,使得可以定制化知识管理,减少不相关的数据,同时提供共同的上下文。这平衡了团队协调与个人效率。
3.3 多代理合作示例
MetaGPT能够从用户的单行指令生成整个软件系统。本节将扩展图2,并使用瀑布式SOP更详细地描述MetaGPT,当提示为"制作2048滑动瓷砖数字拼图游戏"时:
Alice(产品经理):准备WritePRD 当老板(用户)提出产品需求时,Alice,产品经理,将起草7份文件,包括:产品目标、用户故事、竞争分析(以文本形式和象限图形式)、需求分析、需求池、UI设计。在Alice可以根据瀑布式SOP将她的工作交接给下一个LLM代理之前,她的工作首先会被审查:
Bob(架构师):准备WriteDesign 根据Alice的需求分析和可行性分析,我们的架构师将为该项目起草一个系统设计计划,该计划从高级实施方法开始:
""" Implementation approach: We will use Python’s built-in libraries for the core game logic. For the GUI, we will use the open-source library Pygame, which is a set of Python modules designed for writing video games. It includes computer graphics and sound libraries. For the high score tracking feature, we will use SQLite, a C library that provides a lightweight disk-based database. SQLite allows us to persist the high score even afterthe game is closed. For testing, we will use Pytest, a mature full-featured Python testing tool. """
根据实施计划,架构师Bob将创建一个文件列表,将计划的复杂逻辑细分到十几个文件中。
["https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//main.py&sa=D&source=editors&ust=1698418149786424&usg=AOvVaw2zZX3EzOoCRi_tbs0NpQl8">main.py", "https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//game.py&sa=D&source=editors&ust=1698418149786857&usg=AOvVaw3ymS-pIjlGFRenfmFSSppW">game.py", "https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//gui.py&sa=D&source=editors&ust=1698418149787138&usg=AOvVaw3RQ0ijNd17vT053GMcB_OQ">gui.py", "https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//database.py&sa=D&source=editors&ust=1698418149787398&usg=AOvVaw2jtko0Fg8tO_GKX264Wvzz">database.py", "test_game.py", "test_gui.py", "test_database.py"]
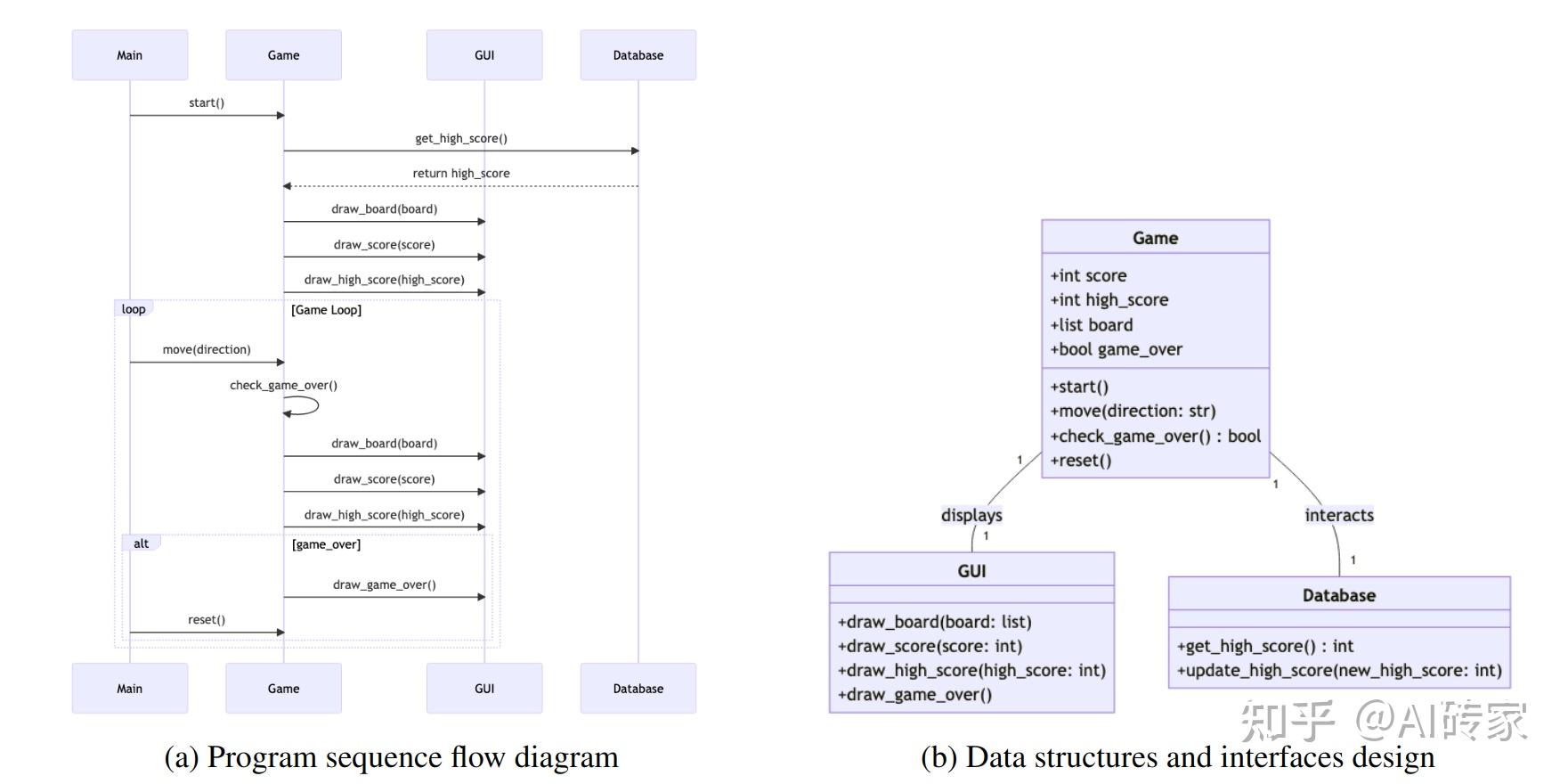
图6:由MetaGPT中的代理Bob自动生成的序列流程图和系统界面设计。
并生成mermaid图表来定义数据结构和接口,以及程序序列流程图,如图6所示。
Bob将根据设计生成文件目录和空文件,并将所有工作(文档和图表)发布到"WriteDesign"类别下的消息队列中。
Eve(项目经理):准备WriteTasks Eve订阅了"WriteDesign"类别,并使用先前起草的UI、系统设计、API设计文档将项目细分为更简单、更具操作性的任务/票据,通常在单个代码文件的复杂性级别上:
## Logic Analysis [ ("https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//main.py&sa=D&source=editors&ust=1698418149788535&usg=AOvVaw0BfE9epnsBHCZI_1VizN02">main.py", "Contains the main game loop and handles user input."), ("https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//game.py&sa=D&source=editors&ust=1698418149788928&usg=AOvVaw3nH8Ga55QfxKMJ6s9cX7Ly">game.py", "Implements the game logic, including the board, score, and game over condition."),
("https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//gui.py&sa=D&source=editors&ust=1698418149789398&usg=AOvVaw0boxgart8Pk6Eyde1O8sbZ">gui.py", "Handles the graphical user interface, including drawing the board, score, and game over screen."), ("https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//database.py&sa=D&source=editors&ust=1698418149789723&usg=AOvVaw3zb_KE_aQ5ECpGapTlMjpu">database.py", "Manages the high score database, including getting and updating the high score."), ("test_game.py", "Tests the game logic."), ("test_gui.py", "Tests the graphical user interface."), ("test_database.py", "Tests the high score database.") ]
## Task list [ "https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//game.py&sa=D&source=editors&ust=1698418149790073&usg=AOvVaw2HdWhP7Ekl_pZlfEmKHNJk">game.py", "https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//database.py&sa=D&source=editors&ust=1698418149790268&usg=AOvVaw37yxSJiyhpOF7rjLxwrK8q">database.py", "https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//gui.py&sa=D&source=editors&ust=1698418149790438&usg=AOvVaw3k7Cz8uIGefKvoapQLdY0f">gui.py", "https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//main.py&sa=D&source=editors&ust=1698418149790606&usg=AOvVaw2aSdMjWPU6FXRxs94NvuzF">main.py", "test_game.py", "test_database.py", "test_gui.py" ]
## Shared Knowledge """ ’https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//game.py&sa=D&source=editors&ust=1698418149790868&usg=AOvVaw3Li28HlIhiVh-xI9POAeRw">game.py’ contains the ’Game’ class, which includes the game logic. ’https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//database.py&sa=D&source=editors&ust=1698418149791064&usg=AOvVaw3GZb1Za78SCgjotJmO5Z0E">database.py’ contains the ’Database’ class, which manages the high score database. ’https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//gui.py&sa=D&source=editors&ust=1698418149791270&usg=AOvVaw2ryKSFAd4IFOwU9oXjL4E0">gui.py’ contains the ’GUI’ class, which handles the graphical user interface. ’https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//main.py&sa=D&source=editors&ust=1698418149791464&usg=AOvVaw01XZUwegh35xn6YfpGS6eP">main.py’ contains the main game loop and handles user input. """
此外,项目经理Eve将列出项目的依赖项,包括用Python以及其他语言编写的第三方包和API规范。当有缺失的细节时,审查/反思过程将在当前阶段迭代地改进生成的内容,直到审查者满意为止。例如:
""" ## Anything UNCLEAR There is no main entry point defined in the project. We need to clarify whether the main game loop will be in ’https://www.google.com/url?q=https://link.zhihu.com/?target%3Dhttp%253A//main.py&sa=D&source=editors&ust=1698418149791794&usg=AOvVaw3X4DUvw8gjQJWYGNMspE6C">main.py’ or in another file. """
Alex(工程师):准备WriteCode和WriteCodeReview。根据"WriteTasks"消息的形式提供的具体任务和连贯的整体实施计划,LLM工程师代理有足够的信息生成无错误的代码。Alex将按给定的顺序浏览文件列表,并生成每个文件及其相应的单元测试。
""" Total running cost: $1.118 | Max budget: $3.000 | Current cost: $0.158, prompt_tokens=4565, completion_tokens=354 Done generating. """
在第一次尝试时,MetaGPT已经成功地生成了一个无错误的2048滑动拼图游戏。所有这些都来自单行用户指令。
图7:2048滑动拼图游戏的MetaGPT生成的运行时界面
4 实验
4.1 任务选择和评估方法
评估指标 为了量化我们的实验结果,我们定义了一些度量标准。
实验设置 我们在Python环境中(版本3.9.6)使用MetaGPT进行了七项多样化的实验。这些实验旨在展示其在各种场景中的多功能性,包括游戏、网页开发和数据分析。MetaGPT版本8cc8b80作为实验代码,GPT4-32k作为底层语言模型。实验具有特定配置:最大令牌消耗限制为1500,投资上限为3,最大迭代次数为5。此外,我们激活了代码审查功能,并使用mermaid.js3进行PDF和图表生成。每个项目经历了一个生成过程。完整的实验记录表格可以在附录B中找到。
为了全面验证MetaGPT框架的优势,我们对MetaGPT进行了超过70项任务的离线实验评估,这些任务旨在评估框架的可行性和普遍适用性。这个涵盖了众多领域和一系列复杂性的任务池是经过精心选择的,目的是提供对MetaGPT潜力的详尽评估。每项任务都使用关键指标进行评估,包括代码统计、文档统计、成本统计、修订成本以及代码执行方面的成功率。为了更深入地了解我们的实验设置和结果,我们在附录B中附加了这些任务的一个子集。简而言之,使用MetaGPT框架平均需要516秒和$1.12来获得一个包含4.71个代码文件、3个PRD和3个文档的项目。在不超过三次的错误修复后,生成的项目的成功率可以达到51.43%。
重要的是要强调,这里呈现的统计数据代表了当前实验套件的结果,并不应被视为确定性的性能基准。MetaGPT的性能可能会根据具体的实验条件和使用的任务配置而有所不同。
4.2 与其他方法的比较
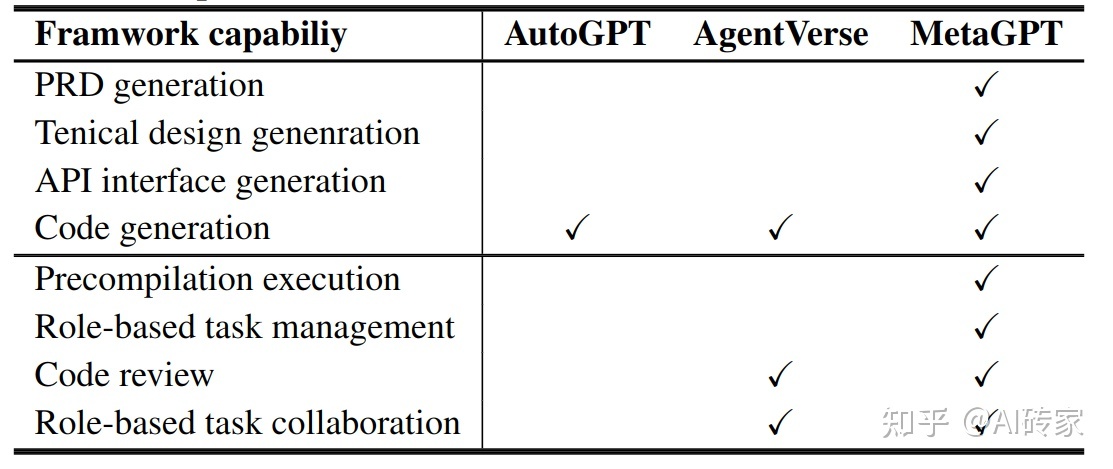
在这部分,我们首先在表1中提供了MetaGPT、AutoGPT和AgentVerse功能的明确比较。然后,我们进行实验来量化不同框架的性能。
框架功能比较
MetaGPT以其广泛的功能脱颖而出。仅MetaGPT具有生成PRD和技术设计的能力,强调其全面的项目执行方法。MetaGPT也是唯一能够进行API界面生成的框架,这在快速API设计原型场景中提供了优势。
代码审查是开发过程的一个关键组成部分,这是MetaGPT和AgentVerse中都有的功能,但AutoGPT中显然缺少。通过加入预编译执行功能,MetaGPT进一步区分了自己,这个功能有助于早期错误检测,从而提高了代码的质量。在协作功能方面,MetaGPT和AgentVerse都支持基于角色的任务协作,这是一种促进多代理协作并通过将任务分配给特定角色来增强团队合作的机制。然而,MetaGPT独家提供基于角色的任务管理功能,这个功能不仅分解任务,还监督它们的管理,从而突显了其全面的项目管理能力。在评估代码生成能力时,这三个框架都表现出熟练性。但是,MetaGPT提供了一个更全面的解决方案,解决了开发过程的更广泛方面,从而为项目管理和执行提供了一个全面的工具集。
这种比较是基于各自框架的当前状态。未来的更新可能会增加或修改这些工具的功能。但从这次分析来看,MetaGPT在为项目执行提供更全面和稳健的解决方案方面超越了其对手。
定量实验比较
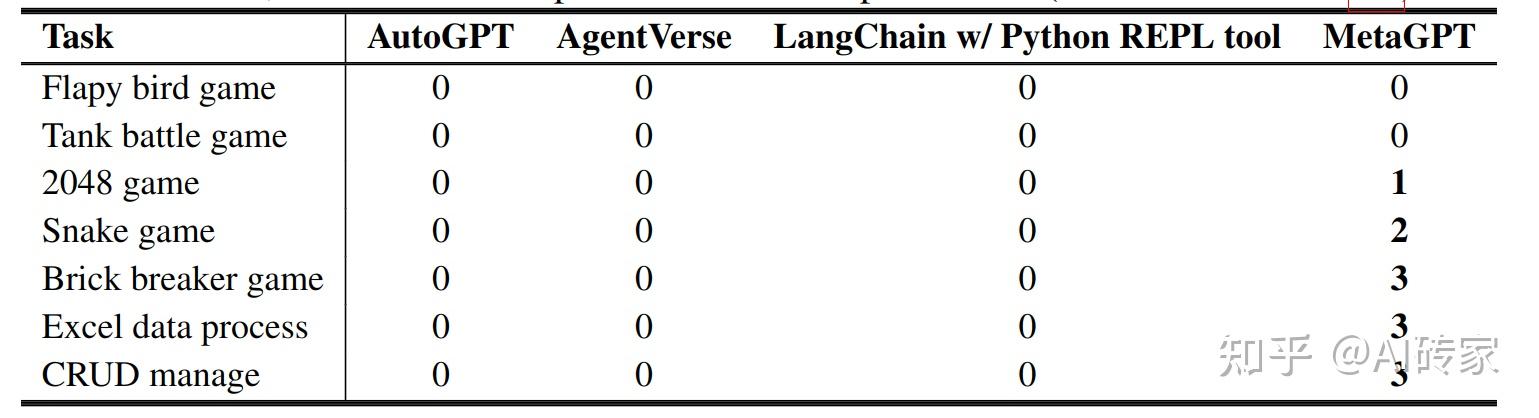
为了评估如MetaGPT、AutoGPT和AgentVerse等不同框架的性能,我们对7个不同的任务进行了实验。这些任务包括Python游戏生成、CRUD代码生成和简单数据分析,这种方法旨在揭示每个受审查的框架的独特优点和缺点。结果显示在表2中。
表1:跨MetaGPT、AutoGPT和AgentVerse的能力比较。注意,“✓”表示在相应的框架中存在给定的功能。
表2:AutoGPT、AgentVerse和MetaGPT之间的任务可执行性比较。任务基于从“0”到“3”的评分系统进行评分,其中“0”表示“完全失败”,“1”表示“可运行代码”,“2”表示“大致预期的工作流程”,“3”表示“完美符合预期”(如第4.1节所示)。
从表2中呈现的数据可以看出,MetaGPT在一系列不同的任务中表现出稳健的性能,只有两个实例(Flappy Bird和Tank Battle)没有成功执行。这些任务有很高的交互需求,由于为手工调整分配的严格约束和有限的资源,MetaGPT没有成功完成它们。与此形成鲜明对比的是,竞争对手框架AutoGPT和AgentVerse在任何任务中都没有实现成功执行,这在MetaGPT框架的有效性方面产生了鲜明的差异。
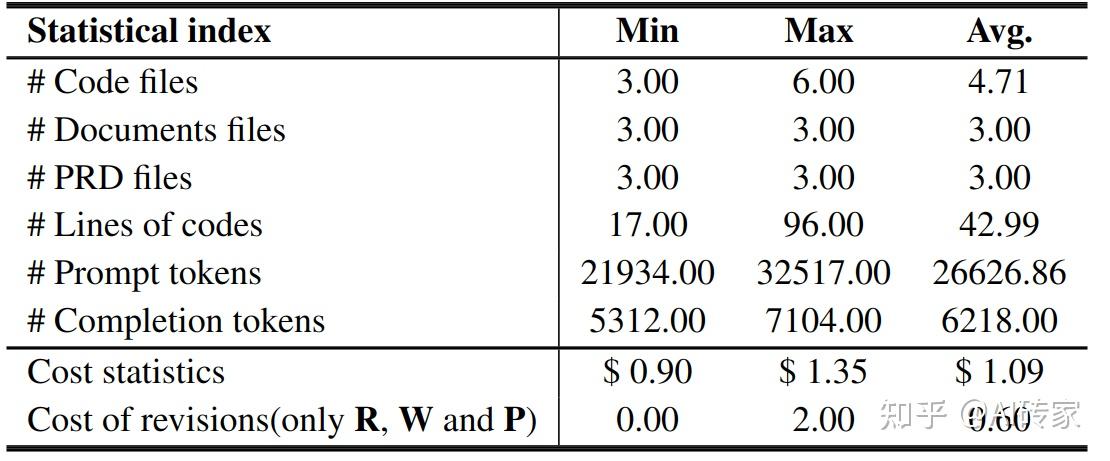
我们还提供了关于MetaGPT的运行时间统计信息,显示在表3中。在上述实验项目中,每个项目平均有4.71个代码文件(包括但不限于如CSS、py、js等格式),每个文件平均有42.99行代码。关于PRD文件,每个项目生成了平均三个PRD文件(考虑到与同名的pdf、mmd和png为一个文件)。此外,对于项目文档,每个项目平均有三个文档,通常包括产品需求文档、API文档和系统架构文档,每个文档平均有80行。
表3:MetaGPT在软件开发中的统计分析。报告了各种统计指标的最小值(Min)、最大值(Max)和平均值(Avg.)。“#”表示“数量”。
在成本分析方面,每个项目在提示上平均消耗了26626.86 tokens,完成任务时消耗了6218.00 tokens,导致完成任务的总成本为$ 1.09。整个构建过程用时517.71秒。与传统的软件工程开发时间线和成本相比,MetaGPT的时间和货币开销不到千分之一。
我们采用Code of Revisions作为解决项目执行期间遇到的错误的指标,这些错误是通过依赖性替换、代码修改或其他纠正措施解决的,直到成功执行或遇到下一个问题。Code of Revision允许的最大次数是三次;超过这个限制,如果继续遇到错误,项目将被视为失败。关于Code of Revisions,每个项目平均需要0.6次修订,大部分问题与依赖关系、资源不可用和参数缺失有关。整体成功率(WP率 - 成功运行并通常满足期望)为57.14%。
尽管AutoGPT目前是最流行的单一代理框架,但在我们的实验中,使用GPT4-32k配置及其默认设置,它无法成功完成任何任务。作为一个单一的代理,其特性必须在执行过程之前手动建立,且这些特性在过程中不能被改变。AutoGPT能够将用户提供的任务分解为多个较小的子任务,并按顺序执行它们。然而,我们在实验过程中的观察突显了AutoGPT的一个重大缺点:它缺乏完整性评估和单一代理的专业知识。
AutoGPT缺乏评估任务完整性的机制。它只是在保存生成的结果后标记任务为完成,而没有进一步检查有效性或完整性。为了尝试创建一个更有效的循环,我们使用了LangChain中的AutoGPT实现,并集成了Python Read-Eval-Print Loop (REPL)工具。我们的意图是使AutoGPT能够调试和优化它编写的代码。然而,代理的专业知识的缺乏使其无法利用解释器提供的反馈来改进其代码。因此,由于生成的代码不完整和非功能性,任务仍然失败。
尽管实施了三个专门的角色:编写者、测试者和评审员,AgentVerse在所有基准任务上都失败了。这些角色以在线评判(OJs)的方式进行合作。AgentVerse内部的对话主要围绕编写者创建代码、测试者在代码执行过程中识别失败或错误消息,以及评审员建议的修改,这与我们在MetaGPT中实现的能够进行编码和代码审查的工程师相似。AgentVerse内部的对话主要关注代码本身,而不是整体任务。然而,缺乏负责将大任务分解为较小、易于管理的任务的角色使AgentVerse处于劣势。这种任务分解和工作分配的缺乏显著降低了成功完成较大、更复杂任务的可能性。AgentVerse的不足强调了在处理复杂问题解决场景中,明确角色划分和策略性任务隔离在不同阶段的重要性。
4.3 消融研究
我们的消融研究涉及系统地减少参与开发过程的角色数量,并随后检查对可执行输出和中间文件有效性的影响。考虑到它们的复杂性需要一个拥有多种角色和多步骤工作流的团队,我们选择了Brick Breaker和Gomoku作为任务,这与游戏开发的现实相似,其特点是明确的角色划分和团队合作。
我们最初的MetaGPT实验是使用一个完全配备的团队进行的,包括四个不同的角色:产品经理、架构师、项目经理和工程师,与第4.1节的实验设置相一致。对于消融研究,我们使用了一套指标:代码文件中的总行数、资金成本、修订成本和代码可执行性,如第4.1节所定义。这些指标被选中是为了直接量化代码生成的质量、任务的性价比和生成代码的功能质量等方面。
在从这个完全配备的团队获得结果后,我们逐渐去除架构师、项目经理和产品经理角色,在后续实验中评估他们的缺席如何影响整体任务性能。
如表4和表5所示,保留三个角色同时去除架构师或项目经理导致代码统计的适度减少,Brick Breaker少了29和14行,Gomoku少了33和47行。此外,还需要额外的1-2次修订。但是,整体任务可执行性大部分得到了保留。当从三个角色转变为只有两个,产品经理和工程师时,代码量的大幅减少和所需修复的增加变得明显。在这种情境下,游戏测试分别显示62和63行的减少,以及2和3次修订的增加。
此外,值得注意的是,当团队减少到一个代理时,代码的可执行性显著下降。即使产生了额外的修订成本,代码仍然是不可执行的。因此,多个角色的存在不仅增强了代码质量,而且加强了代码实现的鲁棒性和可行性。
总之,通过跨条件的定量比较,我们强调了专业化多代理框架对复杂任务的优势。这验证了角色模块化和合作对整体任务完成的重要性。
表4:Brick Breaker游戏开发中的角色减除研究。“#”表示“数量”、“Product”表示“产品经理”、“Project”表示“项目经理”。 “F”表示“完全失败”,“R”表示“可运行代码”,“W”表示“大致预期的工作流程”,“P”表示“完美”。
表5:Gomoku游戏开发中的角色减除研究。“#”表示“数量”、“Product”表示“产品经理”、“Project”表示“项目经理”。 “F”表示“完全失败”,“R”表示“可运行代码”,“W”表示“大致预期的工作流程”,“P”表示“完美”。
5 讨论和未来工作
尽管MetaGPT在自动化端到端过程中具有巨大的潜力,但它也有几个局限性。首要的是,它偶尔会引用不存在的资源文件,如图像和音频。此外,在执行复杂任务时,它容易调用未定义或未导入的类或变量。这些现象被广泛归因于大型语言模型中固有的幻觉倾向,并可以通过更清晰、高效的代理合作流程来处理。
6 结论
在这项工作中,我们介绍了MetaGPT,一个通过SOPs管理LLMs模仿有效的人类工作流程的协同代理的有前景的框架。为了将SOPs编码为提示,MetaGPT通过角色定义、任务分解、流程标准化和其他技术设计来管理多代理,并最终仅使用一行要求完成端到端的开发过程。我们在软件开发中的示例展示了这一框架的潜力,详细的SOPs和提示。实验结果表明,我们的MetaGPT可以产生与现有的基于对话和聊天的多代理系统相对更具有连贯性的全面解决方案。我们相信这项工作为多代理之间的交互和合作开辟了新的可能性,重新定义了复杂问题解决的格局,并指出了通向人工通用智能的潜在途径。