AutoGen介绍
AutoGen官方文档:
AutoGen例子列表:
AutoGen介绍:
AutoGen Github:
介绍:
AutoGenSDK
AutoGen是一个框架,它支持使用多个代理开发LLM应用程序,这些代理可以相互交谈以解决任务。AutoGen 代理是可定制的、可对话的,并且无缝地允许人工参与。它们可以在各种模式下运行,这些模式采用LLM,人工输入和工具的组合。
AutoGen 由 Microsoft、宾夕法尼亚州立大学和华盛顿大学的合作研究提供支持。
从点安装: .在安装中查找更多选项。 对于代码执行,
我们强烈建议安装 python docker 包,并使用 docker。pip install pyautogen
Autogen 支持具有通用多代理对话框架的下一代 LLM 应用程序。它提供可定制和可对话的代理,
例如,
from autogen import AssistantAgent, UserProxyAgent, config_list_from_json
# Load LLM inference endpoints from an env variable or a file
# See https://microsoft.github.io/autogen/docs/FAQ#set-your-api-endpoints
# and OAI_CONFIG_LIST_sample.json
config_list = config_list_from_json(env_or_file="OAI_CONFIG_LIST")
assistant = AssistantAgent("assistant", llm_config={"config_list": config_list})
user_proxy = UserProxyAgent("user_proxy", code_execution_config={"work_dir": "coding"})
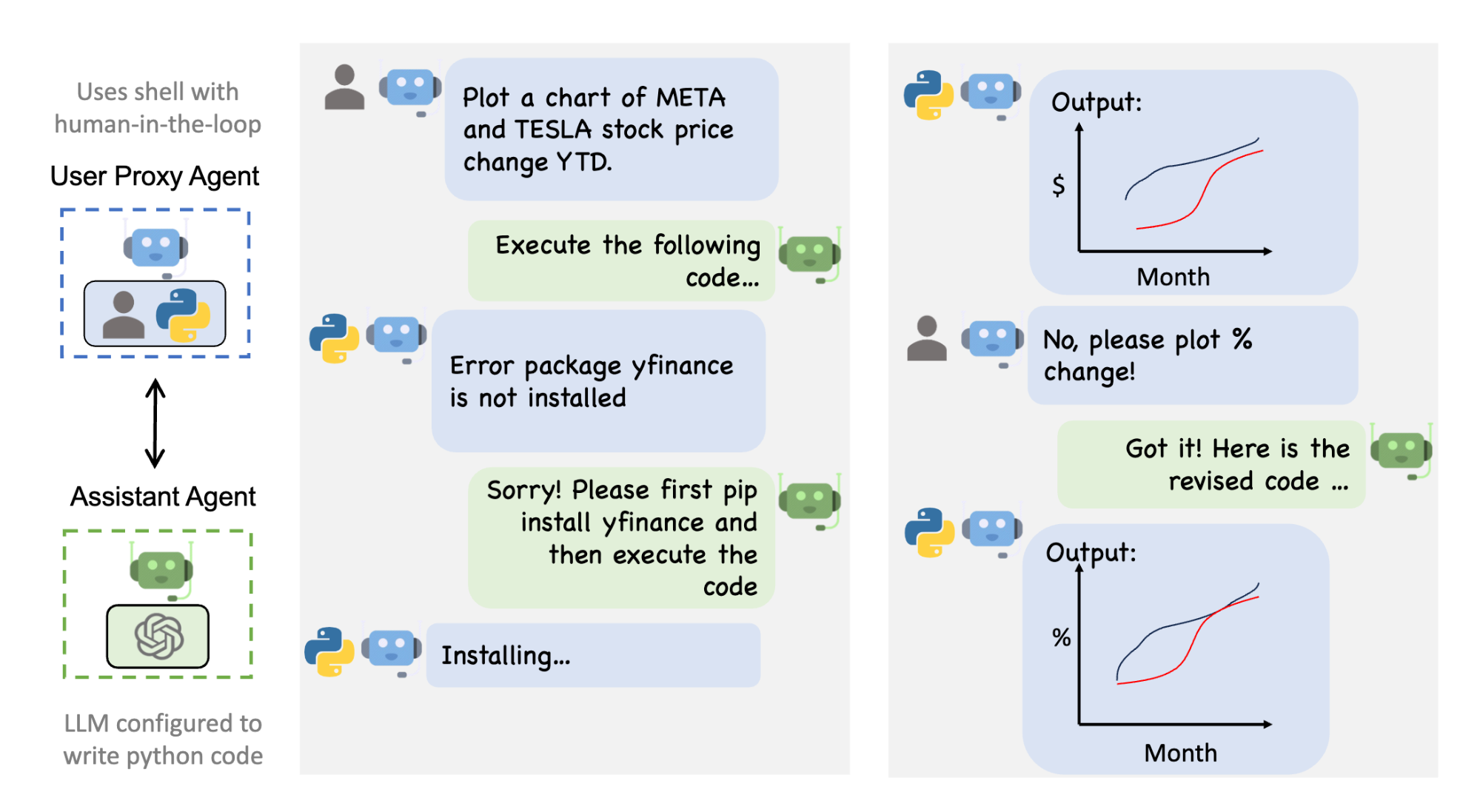
user_proxy.initiate_chat(assistant, message="Plot a chart of NVDA and TESLA stock price change YTD.")
# This initiates an automated chat between the two agents to solve the task
下图显示了使用 AutoGen 的对话流示例。
Autogen还有助于最大化昂贵的LLM(如ChatGPT和GPT-4)的效用。它通过强大的功能(如调优、缓存、错误处理、模板)提供增强的 LLM 推理。例如,您可以使用自己的调优数据、成功指标和预算通过 LLM 优化世代。
# perform tuning
config, analysis = autogen.Completion.tune(
data=tune_data,
metric="success",
mode="max",
eval_func=eval_func,
inference_budget=0.05,
optimization_budget=3,
num_samples=-1,
)
# perform inference for a test instance
response = autogen.Completion.create(context=test_instance, **config)
https://microsoft.github.io/autogen/docs/Use-Cases/agent_chat
AutoGen 提供了一个统一的多代理对话框架,作为使用基础模型的高级抽象。
它具有功能强大,可定制和可对话的代理,通过自动代理聊天集成LLM,工具和人员。
通过自动化多个有能力的代理之间的聊天,可以轻松地让他们集体自主或根据人工反馈执行任务,包括需要通过代码使用工具的任务。
该框架简化了复杂LLM工作流程的编排,自动化和优化。它最大限度地提高了LLM模型的性能并克服了它们的弱点。它能够以最小的工作量构建基于多代理对话的下一代LLM应用程序。
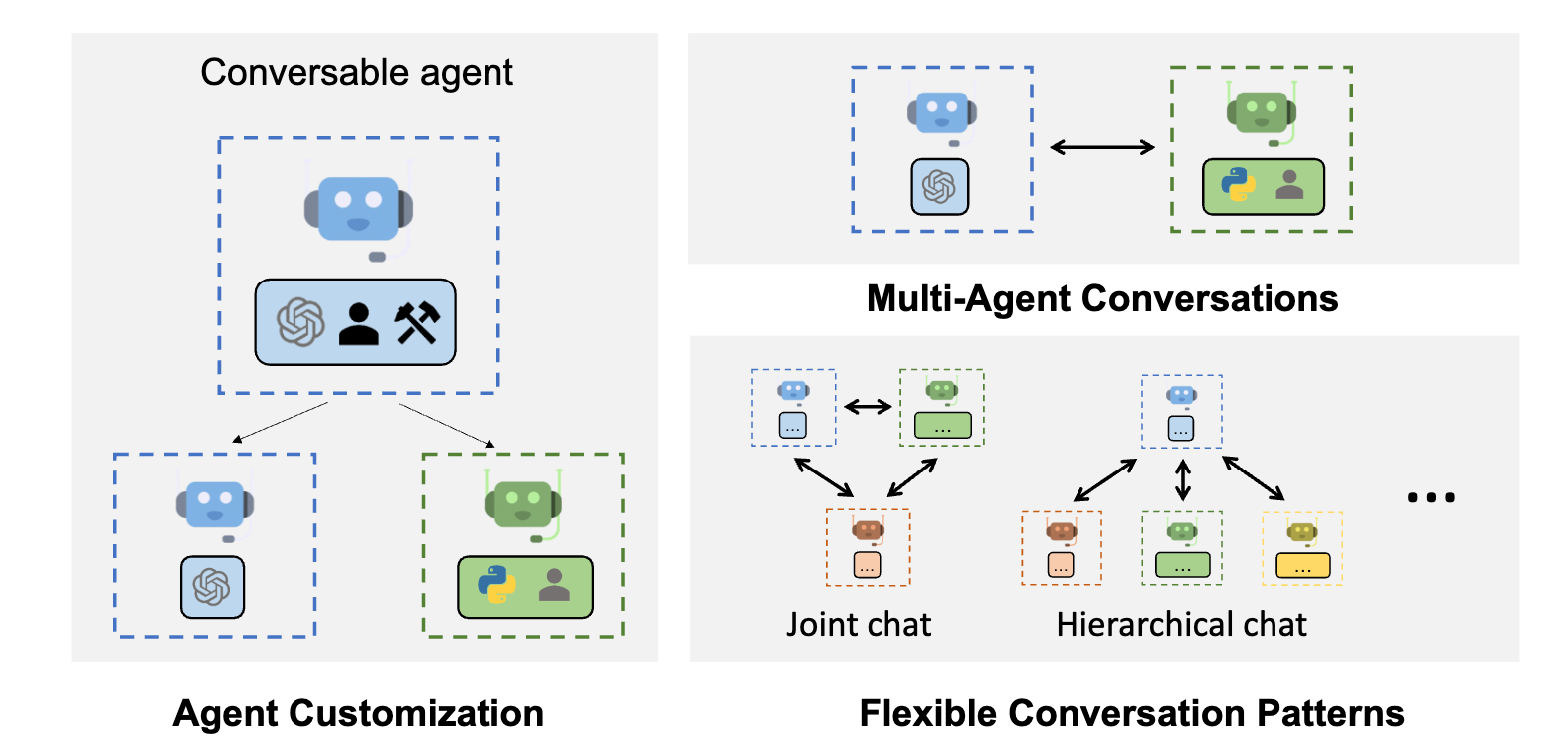
AutoGen 抽象并实现可对话代理 旨在通过代理间对话解决任务。具体来说,AutoGen 中的代理具有以下显着功能:
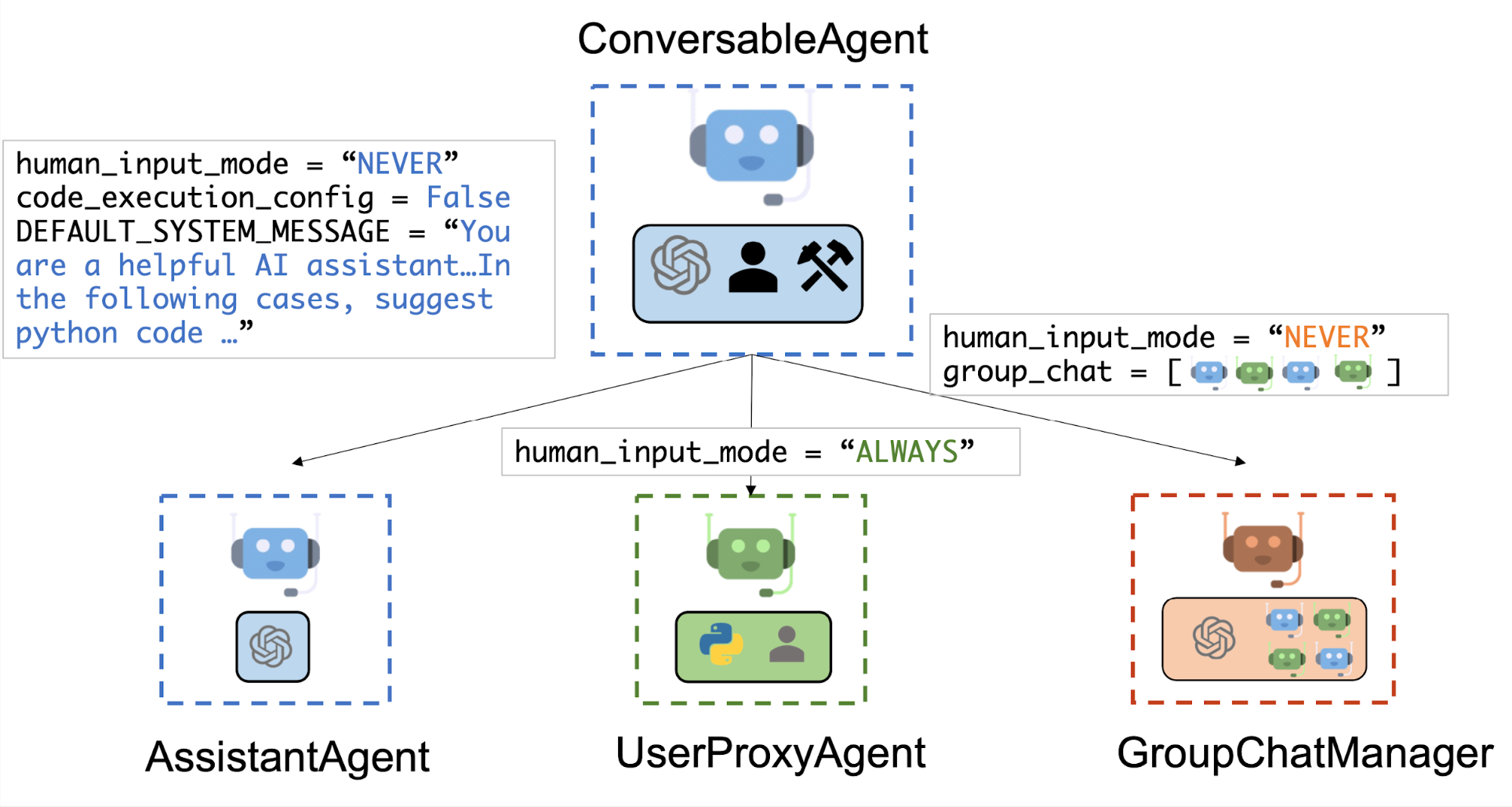
下图显示了自动生成中的内置代理。
我们为代理设计了一个通用类 ConversableAgent,这些代理能够通过交换消息相互交谈以共同完成任务。代理可以与其他代理通信并执行操作。不同的代理在收到消息后执行的操作可能有所不同。两个代表性的子类是AssistantAgent 和UserProxyAgent
ConversableAgent的自动回复功能允许更自主的多代理通信,同时保留人为干预的可能性。 还可以通过使用该方法注册回复函数register_reply()来轻松扩展它。
在下面的代码中,我们创建了一个名为“assistant”的AssistantAgent助手,并创建了一个名为“user_proxy”UserProxyAgent作为人类用户的代理。稍后我们将使用这两个代理来解决任务。
from autogen import AssistantAgent, UserProxyAgent # create an AssistantAgent instance named "assistant" assistant = AssistantAgent(name="assistant") # create a UserProxyAgent instance named "user_proxy" user_proxy = UserProxyAgent(name="user_proxy") |
正确构造参与代理后,可以通过初始化步骤启动多代理会话会话,如以下代码所示:
# the assistant receives a message from the user, which contains the task description user_proxy.initiate_chat( assistant, message="""What date is today? Which big tech stock has the largest year-to-date gain this year? How much is the gain?""", ) |
在初始化步骤之后,对话可以自动进行。在下面找到user_proxy和助手如何协作自主解决上述任务的直观说明:
一方面,可以在初始化步骤后实现完全自主的对话。另一方面,AutoGen 可用于通过配置人工参与级别和模式(例如,设置human_input_mode为 。ALWAYS)来实现人工参与问题解决,因为在许多应用中需要和/或需要人工参与
通过采用编程语言和自然语言的对话驱动控件,AutoGen 本质上允许动态对话。动态会话允许代理拓扑根据不同输入问题实例下的实际会话流进行更改,而静态会话的流始终遵循预定义的拓扑。动态对话模式在无法预先确定交互模式的复杂应用程序中非常有用。AutoGen 提供了两种实现动态对话的常规方法:
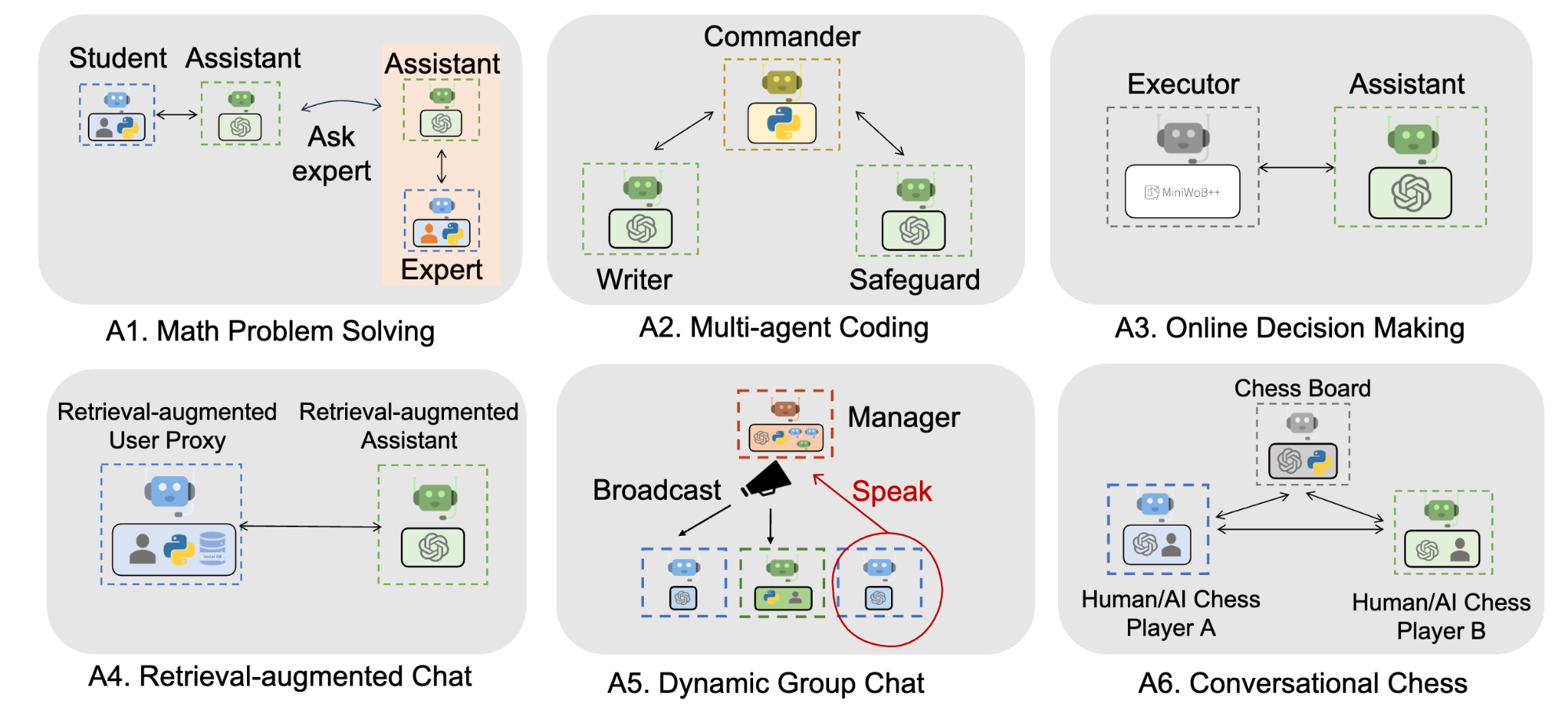
下图显示了使用 AutoGen 构建的六个应用程序示例------SOP
autogen.Completion是增强型LLM推理的直接替代品。 用于执行推理有许多好处:性能调优、API 统一、缓存、错误处理、多配置推理、结果过滤、模板化等。openai.Completionopenai.ChatCompletionautogen
使用基础模型生成文本的成本通常根据输入和输出中的标记数组合来衡量。从使用基础模型的应用程序构建器的角度来看,用例是在推理预算约束下最大化生成文本的效用(例如,通过解决编码问题所需的平均美元成本来衡量)。这可以通过优化推理的超参数来实现, 这会显着影响生成文本的效用和成本。
可调超参数包括:
文本生成的成本和效用与这些超参数的共同效应交织在一起。 超参数的子集之间也存在复杂的交互。例如 不建议将温度和top_p从其默认值一起更改,因为它们都控制生成文本的随机性,并且同时更改两者可能会导致冲突效果;n 和 best_of 很少一起调优,因为如果应用程序可以处理多个输出,则在服务器端进行过滤会导致不必要的信息丢失;n 和 max_tokens 都会影响生成的令牌总数,进而影响请求的成本。 这些交互和权衡使得手动确定给定文本生成任务的最佳超参数设置变得困难。
使用 AutoGen,可以使用以下信息执行调整:
收集一组不同的实例。它们可以存储在可迭代的字典中。例如,每个实例字典可以包含“问题”作为键,并将数学问题的描述str作为值;“解决方案”作为键,解决方案str作为值。
评估函数应将响应列表以及与每个验证数据实例中的键对应的其他关键字参数作为输入,并输出指标字典。例如
def eval_math_responses(responses: List[str], solution: str, **args) -> Dict: # select a response from the list of responses answer = voted_answer(responses) # check whether the answer is correct return {"success": is_equivalent(answer, solution)} |
autogen.code_utils并autogen.math_utils提供一些用于代码生成和数学问题解决的示例评估函数。
要优化的指标通常是所有优化数据实例的聚合指标。例如,用户可以指定“成功”作为指标,将“max”指定为优化模式。默认情况下,聚合函数取平均值。如果需要,用户可以提供自定义的聚合功能。
用户可以为每个超参数指定(可选)搜索范围。
或 flaml.tune.lograndint指定。默认情况下,max_tokens在 [50, 1000] 中搜索;在 [1, 100] 中搜索 n;best_of固定为 1。
停。它可以是 str 或 str 列表,也可以是 str 列表列表或 None。默认值为“无”。
可以指定推理预算和优化预算。 推理预算是指每个数据实例的平均推理成本。 优化预算是指调优过程中允许的总预算。两者都以美元衡量,并遵循每 1000 个代币的价格。
现在,您可以用于调整。例如autogen.Completion.tune
import autogen config, analysis = autogen.Completion.tune( data=tune_data, metric="success", mode="max", eval_func=eval_func, inference_budget=0.05, optimization_budget=3, num_samples=-1, )
|
num_samples是要采样的配置数。-1 表示无限制(直到优化预算用尽)。 返回的包含优化的配置,并包含所有尝试的配置和结果的 ExperimentAnalysis 对象。configanalysis
tuend 配置可用于执行推理。
autogen.Completion.create与 和 以及 OpenAI API 和 Azure OpenAI API 兼容。因此,诸如“text-davinci-003”,“gpt-3.5-turbo”和“gpt-4”之类的模型可以共享一个通用的API。 当使用聊天模型并作为输入时,提示将自动转换为 以满足聊天完成 API 要求。一个优点是,可以在统一的 API 中针对同一提示试验聊天和非聊天模型。openai.Completion.createopenai.ChatCompletion.createpromptautogen.Completion.createmessages
对于本地LLM,可以使用FastChat等包启动端点,然后使用相同的API发送请求。
当仅使用基于聊天的模型时,可以使用。如果提供提示而不是消息,它还会自动从提示转换为消息。autogen.ChatCompletion
API 调用结果在本地缓存,并在发出相同请求时重复使用。这在重复或继续实验以实现可重复性和节省成本时非常有用。它仍然允许通过设置“种子”,使用或指定 .set_cachecreate()
由于连接、速率限制或超时,调用 OpenAI API 时很容易遇到错误。有些错误是暂时性的。 处理暂时性错误并自动重试。请求超时、最大重试时间和重试等待时间可通过 和 进行配置。autogen.Completion.createrequest_timeoutmax_retry_periodretry_wait_time
此外,可以传递不同模型/端点的配置列表,以减轻速率限制。例如
response = autogen.Completion.create( config_list=[ { "model": "gpt-4", "api_key": os.environ.get("AZURE_OPENAI_API_KEY"), "api_type": "azure", "api_base": os.environ.get("AZURE_OPENAI_API_BASE"), "api_version": "2023-07-01-preview", }, { "model": "gpt-3.5-turbo", "api_key": os.environ.get("OPENAI_API_KEY"), "api_type": "open_ai", "api_base": "https://api.openai.com/v1";, "api_version": None, }, { "model": "llama-7B", "api_base": "http://127.0.0.1:8080";, "api_type": "open_ai", "api_version": None, } ], prompt="Hi", ) |
它将尝试逐个查询Azure OpenAI gpt-4,OpenAI gpt-3.5-turbo和本地托管的llama-7B,忽略AuthenticationError,RateLimitError和Timeout。 直到返回有效结果。这可以加快速率限制是瓶颈的开发过程。如果最后一个选择失败,将引发错误。因此,请确保列表中的最后一个选项具有最佳可用性。
为了方便起见,我们提供了许多实用程序函数来加载配置列表,例如config_list_from_json: 像上面的字典列表这样的配置列表可以保存在环境变量或 json 格式的文件中,并加载此函数。
另一种类型的错误是返回的响应不满足要求。例如,如果响应需要是有效的 json 字符串,则希望过滤不是的有效响应。这可以通过提供配置列表和过滤功能来实现。例如
def valid_json_filter(context, config, response): for text in autogen.Completion.extract_text(response): try: json.loads(text) return True except ValueError: pass return False response = autogen.Completion.create( config_list=[{"model": "text-ada-001"}, {"model": "gpt-3.5-turbo"}, {"model": "text-davinci-003"}], prompt="How to construct a json request to Bing API to search for 'latest AI news'? Return the JSON request.", filter_func=valid_json_filter, )
|
上面的示例将尝试迭代使用 text-ada-001、gpt-3.5-turbo 和 text-davinci-003,直到返回有效的 json 字符串或使用最后一个配置。还可以多次重复列表中的同一模型,以多次尝试一个模型,以提高最终响应的鲁棒性。
如果提供的提示或消息是模板,它将在给定的上下文中自动具体化。例如
response = autogen.Completion.create( context={"problem": "How many positive integers, not exceeding 100, are multiples of 2 or 3 but not 4?"}, prompt="{problem} Solve the problem carefully.", allow_format_str_template=True, **config ) |
模板可以是格式 str,如上例所示,也可以是从多个输入字段生成 str 的函数,如下例所示。
def content(turn, context): return "\n".join( [ context[f"user_message_{turn}"], context[f"external_info_{turn}"] ] ) messages = [ { "role": "system", "content": "You are a teaching assistant of math.", }, { "role": "user", "content": partial(content, turn=0), }, ] context = { "user_message_0": "Could you explain the solution to Problem 1?", "external_info_0": "Problem 1: ...", } response = autogen.ChatCompletion.create(context, messages=messages, **config) messages.append( { "role": "assistant", "content": autogen.ChatCompletion.extract_text(response)[0] } ) messages.append( { "role": "user", "content": partial(content, turn=1), }, ) context.append( { "user_message_1": "Why can't we apply Theorem 1 to Equation (2)?", "external_info_1": "Theorem 1: ...", } ) response = autogen.ChatCompletion.create(context, messages=messages, **config) |
在调试或诊断基于 LLM 的系统时,记录 API 调用并对其进行分析通常很方便。 并提供一种收集 API 调用历史记录的简单方法。例如,要记录聊天历史记录,只需运行:autogen.Completionautogen.ChatCompletion
autogen.ChatCompletion.start_logging()
在此之后进行的 API 调用将自动记录。它们可以随时通过以下方式检索:
autogen.ChatCompletion.logged_history
有一个函数可用于打印使用情况摘要(每个模型的总成本和令牌计数使用情况):
autogen.ChatCompletion.print_usage_summary()
要停止日志记录,请使用
autogen.ChatCompletion.stop_logging()
如果要将历史记录附加到现有字典中,请按如下方式传递字典:
autogen.ChatCompletion.start_logging(history_dict=existing_history_dict)
默认情况下,API 调用的计数器将在 重置。如果不需要复位,请设置 。start_logging()reset_counter=False
有两种类型的日志记录格式:紧凑日志记录和单个 API 调用日志记录。默认格式为紧凑格式。 设置以切换。
compact=Falsestart_logging()
{
"""
[
{
'role': 'system',
'content': system_message,
},
{
'role': 'user',
'content': user_message_1,
},
{
'role': 'assistant',
'content': assistant_message_1,
},
{
'role': 'user',
'content': user_message_2,
},
{
'role': 'assistant',
'content': assistant_message_2,
},
]""": {
"created_at": [0, 1],
"cost": [0.1, 0.2],
}
}
{
0: {
"request": {
"messages": [
{
"role": "system",
"content": system_message,
},
{
"role": "user",
"content": user_message_1,
}
],
... # other parameters in the request
},
"response": {
"choices": [
"messages": {
"role": "assistant",
"content": assistant_message_1,
},
],
... # other fields in the response
}
},
1: {
"request": {
"messages": [
{
"role": "system",
"content": system_message,
},
{
"role": "user",
"content": user_message_1,
},
{
"role": "assistant",
"content": assistant_message_1,
},
{
"role": "user",
"content": user_message_2,
},
],
... # other parameters in the request
},
"response": {
"choices": [
"messages": {
"role": "assistant",
"content": assistant_message_2,
},
],
... # other fields in the response
}
},
}
Total cost: <cost>
Token count summary for model <model>: prompt_tokens: <count 1>, completion_tokens: <count 2>, total_tokens: <count 3>
可以看出,单个 API 调用历史记录包含会话的冗余信息。对于长时间的对话,冗余程度很高。 紧凑的历史记录更高效,单个 API 调用历史记录包含更多详细信息。